GG修改器破解版下载地址:https://ghb2023zs.bj.bcebos.com/gg/xgq/ggxgq?GGXGQ
大家好,今天小编为大家分享关于gg修改器让游戏加速_gg修改器让游戏加速器的内容,赶快来一起来看看吧。
机器之心报道
机器之心编辑部
深度学习时代的推荐系统,腾讯完成了「破局」。
在现代社会,网络购物、订餐以及其他各种形式的在线消费已经成为了日常生活的重要组成部分。在享受便利生活的同时,人们有时不得不受困于浩瀚复杂的信息和数据。这时,对个性化和智能化推荐系统(mender System)的需求变得日益强烈。这些系统能够有效解决信息过载问题,根据用户历史偏好和约束更精准地推荐个性化物品,从而提升用户体验。而随着深度学习应用的爆发式发展,基于深度学习的推荐得到了越来越多的关注。

深度学习推荐系统(DLRS)已经成为 Meta、谷歌、英伟达等科技巨头的主要基础设施。DLRS 通常包含一大组托管在大量 ML 模型和深度神经网络上的参数服务器,它们通过在地理分布式数据中心的复制来实现客户端的容错和低延迟通信。其中,每个数据中心具有的一组推理服务器从本地参数服务器中提取模型并为客户端输出推荐结果。
为了确保及时地服务于新用户和内容,DLRS 必须不断地以低延迟更新 ML 模型。然而在现有 DLRS 系统中做到这一点并不容易。英伟达 Merlin、谷歌 TFRA 以及 Meta BigGraph 等流行推荐系统采用离线方式更新模型,在收集到新的训练数据后离线计算模型梯度,验证模型检查点并传播到所有数据中心,整个过程需要几分钟甚至是几小时。另一种替代方法使用广域网(WAN)优化的 ML 系统或联邦学习系统,它们使用本地收集的数据更新复制的模型并对副本进行惰性同步,往往会对 SLO(服务等级目标)造成不利影响。
面对现有 DLRS 的种种限制,难道就没有破局之法吗?在 7 月 11 日 – 13 日举办的第 16 届 OSDI 2022 会议上,腾讯与爱丁堡大学等科研机构合作完成的一项研究实现了破局。研究者推出了一种既不牺牲 SLO 又能实现低延迟模型更新的大规模深度学习推荐系统—Ekko,其速度比当前 SOTA DLRS 系统实现数量级提升,并且早已部署在了腾讯的生产环境中,为用户提供各类推荐服务。
OSDI(操作系统设计与实现研讨会,Operating Systems Design and Implementation)是计算机系统软件领域全球最顶级会议之一,被誉为操作系统原理领域的奥斯卡,拥有极高的学术地位,由 USENIX 主办。据了解,本届会议共 253 篇投稿论文,接收 49 篇,接收率约为 19.4%。《Ekko: A Large-Scale Deep Learning mender System with Low-Latency Model Update》成为了腾讯首篇入选该会议的论文。

论文地址:https://www.usenix.org/system/files/osdi22-sima.pdf
接下来,我们将对腾讯推出的这个大规模深度学习推荐系统 Ekko 进行详细的解读。
设计思路与系统概述
首先来看设计思路。为了在不牺牲 SLO 的情况下实现低延迟模型更新,研究者允许训练服务器在线更新模型(使用梯度)并立即将模型更新传播至所有推理集群,从而绕过了长延迟更新步骤,包括离线训练、模型检查点、验证和传播,进而降低模型更新延迟。
为了实现这一设计,研究者需要解决以下几个挑战:
最终,研究者设计出了一个以低延迟对副本模型进行全局更新的大规模深度学习推荐系统 Ekko。其中在设计过程中主要在以下三个方面进行了创新。
首先设计了一种高效的点对点模型更新传播算法。现有参数服务器往往采用 primary-backup 数据复制协议来实现模型更新,但当处理大规模模型更新时,这种方式因长更新延迟和 leader 瓶颈而导致扩展性不足。因此,研究者探索通过点对点的方式来进行模型更新传播,利用更新 DLRS 模型过程中的稀疏性和时间局部性来提高更新模型的吞吐量,降低更新模型的延迟。
其次,Ekko 提供了一个 SLO 保护机制。Ekko 允许模型更新在不需要离线模型验证也能达到推理集群,不过这种设计会导致 SLO 在生产环境中容易受到网络拥塞和有偏更新的影响。因此,为了处理网络拥塞,研究者设计了一个 SLO 感知的模型更新调度器,其计算指标包括更新新鲜度优先级、更新重要性优先级和模型优先级。这些指标都能预测模型更新对推理 SLO 的影响,基于它们,调度器在线计算每个模型更新的优先级。研究者将调度器集成到参数服务器,而不改变 Ekko 中点到点模型更新传播的去中心化架构。
最后,Ekko 使用一种新颖的推理模型状态管理器来处理有偏更新,该管理器为每组推理模型创建了一个基线模型。然后,基线模型接收少量用户流量,并作为推理模型的真值。同时,管理器持续为基线和推理模型监控与质量相关的 SLO。当有偏模型更新破坏了推理模型的状态时,管理器会通知见证服务器将模型回滚到健康状态。
Ekko 的效果究竟如何呢?研究者利用测试台和大规模生产集群对它进行了评估。其中测试台实验结果表明,与 SOTA 参数服务器相比,Ekko 将模型更新延迟最高降低了 7 倍。
研究者进一步使用 40TB 的模型和地理分布区域内的 4600 多台服务器上进行大规模生产实验,结果表明,Ekko 在实现 2.4 秒传播更新的同时每秒执行 10 亿次更新。Ekko 仅将总网络带宽的 3.0% 用于同步,余下部分用于训练和推理。这种秒级延迟性能比 SOTA DLRS 基础设施(如 TFRA 和 Check-N-Run)实现的分钟级延迟快了几个数量级。
Ekko 系统架构:实现低延迟模型更新
Ekko 是一个地理分布式(geo-distributed) 的 DLRS,其能更新中央数据中心的模型。然后,它将更新的模型传播到靠近全球用户的地理分布式数据中心。Ekko 将模型表示为键 – 值对,并将模型划分为分片(shard)。此外,Ekko 将模型分片存储在键 – 值存储中(在 Ekko 中称为参数存储),参数存储通过哈希将键 – 值对分配给分片。
Ekko 使用基于软件的路由器将参数请求定向到模型分片。路由器将训练 DC 中的参数服务器指定为模型分片的主节点(primaries),并且确保主节点的选择可以平衡参数请求的工作负载。路由器的实现遵循典型的键 – 值存储和数据库。
在路由器中有分片管理器,可以处理资源过载、故障域和副本集问题。与传统的分片管理器不同,Ekko 的分片管理器实现了几个特定于 DLRS 的优化:
架构概览
下图 2 为 Ekko 架构概览。正如我们所看到的,Ekko 使参数服务器实现高效的点对点(P2P)模型更新。P2P 模型更新算法防止中央训练数据中心传播更新的模型。相反它使用数据中心内部和跨数据中心的所有网络路径 (图中的实线),从而在传播模型更新时实现高吞吐量。无需使用中央协调器,每个数据中心都可以独立选择同步模型更新的优化间隔。

Ekko 支持大规模模型更新的并发传播,不过这些更新可能会争夺网络资源,从而延迟有利于 SLO 的更新。为了解决这个问题,Ekko 依赖于 SLO 感知模型更新调度器,此调度器预测每个模型更新将如何影响推理结果。预测结果有助于计算模型更新的优先级。根据优先级,Ekko 可以协调哪些模型更新首先在训练数据中心传播,从而提高推理服务器上 SLO 的总体满意度。
Ekko 还可以保护推理服务器免受有害模型更新的影响。为了实现这一点,Ekko 在推理集群中运行了一个模型状态管理器。此模型状态管理器可以监控 SLO 相关指标。
高效的 P2P 模型更新
为了在参数服务器中实现 P2P 模型更新,Ekko 的设计实现了以下目标:
Ekko 需要协调大量(如数千个)参数服务器(部署在全球范围内)以完成模型更新。为了避免滞后者(可能由于慢网络引起),该研究为 Ekko 中的参数服务器设计了 log-less 同步。
作为共享 DLRS,Ekko 需要托管数千个模型。这些模型可以在线生成大量(例如每秒数十亿次)更新。为了支持这一点,Ekko 使参数服务器能够通过点(Peer)有效地发现模型更新并拉取更新,而无需使用过多的计算和网络资源。
Ekko 需要支持地理分布式部署,这通常涉及跨 WAN 和服务器 / 网络故障的异构网络路径。为了支持这一点,Ekko 的系统设计提高了通过 WAN 发送模型更新的吞吐量 / 延迟,并容忍服务器 / 网络故障。
下图 3 显示了在 Ekko 中更新模型所涉及的组件和步骤。假设我们要在两个副本(由副本 1 和副本 2 表示)之间同步一个分片(由分片 1 表示)。与所有其他分片类似,分片 1 具有 (i) 概括参数更新的分片信息,以及 (ii) 基于参数版本追踪模型更新的更新缓存。每个分片还关联一个分片版本,这个版本告诉分片是否可能有参数来同步。分片信息、更新缓存和分片版本共同加速参数服务器之间的参数同步。

为了完成模型更新,副本 2 向副本 1 ( 1 ) 请求最近修改的分片版本。收到请求后,副本 1 返回最近修改的分片版本列表 (2)。副本 2 然后将副本 1 的所有分片版本与本地分片版本进行比较,然后将相关的分片知识发送到副本 1 ( 3 )。最后,副本 1 将所有更新的参数发送到副本 2 ( 4 )。按照这些步骤,Ekko 可以确保模型更新最终以低延迟(即最终一致性)传播到所有副本。
SLO 保护机制
DLRS 有两种主要的 SLO 类型:Freshness SLO 和 Quality SLO 。图 4 描述了推理服务器如何影响 SLO 的 freshness 和 quality。
一旦接收到请求,推理服务器就会选择相关用户和条目嵌入。然后聚合嵌入,并将聚合嵌入发送给 DNN,后者返回推荐条目分数,DLRS 最终返回一个按分数排序的条目列表。
在这种情况下,Freshness SLO 是根据推荐条目的最新时间戳来衡量的(在理想情况下,这个时间戳应该尽可能接近当前时间)。Quality SLO 可以根据条目的查看时间和点击数量来衡量。在实践中,Ekko 在线维护了大量的 Freshness SLO 和 Quality SLO。
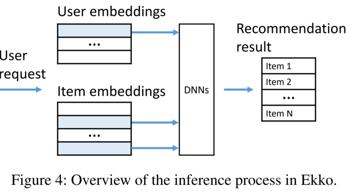
Ekko 可以防止 Freshness SLO 、Quality SLO 受到网络拥塞的影响,这是通过 SLO 感知模型更新调度器以及将该调度器集成到 P2P 模型更新传播来实现的。
如下算法 2 描述了使用优先级调度器增强的 log-less P2P 同步:

Ekko 使用推理模型状态管理器来保护 SLO 免受有害的模型更新。该管理器监控推理模型的健康状况(即 quality SLO)并按需进行低延迟模型状态回滚。下图 5 说明了回滚模型状态的过程。

测试台实验
在评估部分,研究者首先在 30 台服务器集群中进行测试台实验,其中每台服务器包含一个 24 核心 CPU、64GB 内存和 5 Gbps 网络连接。他们将每 3 台服务器分组为一个 DC 以模拟多 DC 场景,因而最多可以构成 10 个 DC。研究者选取其中一个面向训练的 DC,其余皆为面向推理的 DC,将它们彼此连接。DC 间带宽为 4800 Mbps,模拟一个 WAN。
此外,测试台实验包含两个工作负载,其中一个用来训练研究者自身生产环境中通常使用的大型排序模型,另一个使用按时间先后排序的 Criteo Terabyte Click Logs 来训练 Wide & Deep 模型。
测试台实验细分为两个评估指标,分别为更新延迟和性能细分。
更新延迟
研究者分别在同构 WAN 和异构 WAN 中评估了 Ekko 的更新延迟,其中使用了两个基线——Adam 和 Checkpoint-Broadcast,后者是在 DLRS 终应用模型更新的实际方法。Ekko 和基线都使用 DRAM 存储,并采用相同的主要分配和负载平衡方案。
先来看同构 WAN,研究者对 Ekko 与 Adam 进行比较。具体地,研究者分别用 1 个 DC(3 副本)、5 个 DC(15 个副本)和 10 个 DC(30 个副本)来测量延迟。结果如下图 6a 和 6b 所示,在生产和 Criteo 工作负载中,Ekko 的延迟明显低于 Adam。并且,当使用运行生产工作负载的 10 个 DC 时,Ekko 实现了 2.6 秒的延迟,这要比 Adam 的 18.8 秒低了 7 倍。

此外,在 Ekko 与 Checkpoint-Broadcast 的比较中,研究者发现,Checkpoint-Broadcast 在 WAN 中同步 4GB 参数需要 7 秒以上,这要比 Ekko 的秒级延迟(如 2.6 秒)长了几个数量级。
接着来看异构 WAN,研究者同样将 Ekko 与基线进行了比较。在异构 WAN 中,他们将 DC 间带宽默认设置为 256 Mbps。结果如下图 7a 和 7b 所示,Ekko 可以有效缓解生产和 Criteo 工作负载中的缓慢异构链路,允许副本以独立速率同步,并维持秒级同步延迟。

性能细分
研究者同样想要了解 Ekko 同步中各个组件的有效性,因此对 10 个 DC 的生产工作负载进行了性能细分分析。他们首先在配置 Ekko 时仅在同步中使用分片知识,成为了实验的基线配置,等同于点对点同步中的 SOTA 系统版本向量(Version Vector, VV)。
结果如下图 8 所示,仅使用 VV,Ekko 需要 76.3 秒来同步所有参数。而当启用更新缓存后,Ekko 将延迟降低到了 27.4 秒,实现了 2.8 倍加速。
然后,通过进一步启用分片版本,Ekko 又将延迟从 27.4 秒降低到了 6.0 秒,实现了 4.6 倍加速。这意味着跳过未更新的分片可以减少同步引起的网络消耗。
最后,在启用 WAN 优化后,Ekko 再次将延迟从 6.0 秒降低到了 2.6 秒,实现了 2.3 倍加速。这表明点对点同步必须考虑 WAN 中每个链路的可用带宽。

生产集群实验
截止目前,腾讯已经在生产中部署 Ekko 长达一年多的时间。生产环境包括分布在 6 个地理分布式 DC 中的 4600 台服务器。今年以来,腾讯使用 Ekko 支持了广泛的推荐服务,包括视频推荐、搜索和广告。每天有超过 10 亿的用户使用这些推荐服务。
因此,研究者特别报告了 Ekko 在其生产环境的性能,同样使用两个评估指标,即模型更新和 SLO 保护机制。
模型更新
研究者选用的生产环境具有数百个 DLRS 模型,共 计40 TB 参数或 2500 亿个键值对。每个参数分片的范围从 0.1 MB 到 20MB,具体取决于模型大小。Ekko 每秒可以执行 10 亿次更新,速度为 212 GB/s。
关于延迟性能,Ekko 仅用 2.4 秒来同步所有 DC 中的参数,训练 DC 仅用了 0.7 秒。同步流量仅占了总网络流量的 3.0%,体现了 Ekko 在参数服务器上作为后台同步服务的有效性。此外,Ekko 的低延迟、高吞吐量性能不影响系统可用性。自部署以来,Ekko 已实现了大于 99.999% 的参数读写操作可用性。
关于更新缓存分析,实验表明:更新缓存只需要在缓存中保留 0.13%-0.2% 的参数,就可以达到 > 99.4% 的命中率(hit ratios)。
研究者选择更新密集型 DLRS 模型来揭示最坏情况下更新局部性的影响。下图 9 显示了在 480 分钟窗口中更新参数的比例。这个时间窗口涵盖了生产 DLRS 一天中最繁忙的时间。

SLO 保护机制的有效性
研究者还进行了 A/B 测试,以评估 Ekko SLO 保护机制的有效性。
A/B 测试结果表明,在实验组中,Ekko 将同步流量减少了 92%,并将重要更新的延迟保持在较低水平。相反,对照组无法区分模型更新,对照组对 SLO 关键更新进行了延迟,并且 SLO 指标下降了 2.32%。
关于在线模型状态回滚,研究者将 Ekko 与检查点恢复(checkpoint-recovery)方法进行比较。
在实验过程中,研究者告知 Ekko 模型状态管理器将 DLRS 模型的状态回滚到 1 分钟前的版本。然后管理器告知所有 witness 服务器识别最近 1 分钟更新的参数。因此,witness 服务器仅重新加载当前状态和早期状态之间的差异。整个回滚操作只需 6.4 秒即可完成。相比之下,检查点恢复方法与模型状态的最新更新无关,结果是检查点恢复方法必须重新加载整个状态,需要 1157 秒才能完成(比 Ekko 慢 180 倍)。

更多细节内容请阅读原论文。
以上就是关于gg修改器让游戏加速_gg修改器让游戏加速器的全部内容,希望对大家有帮助。

gg修改器免root版2022,gg修改器免root版2022年最新版v101.1 大小:6.00MB7,970人安装 有一种朋友不在生活里,却在生命里;有一种陪伴不在你身边,却在你心间。 大家好,今……
下载
华为gg修改器root权限,华为GG修改器:强大的ROOT权限工具 大小:11.04MB6,716人安装 华为GG修改器是一款安卓手机ROOT权限工具,可以帮助用户快速获取ROOT权限。它能够让……
下载
gg修改器怎么变成中文,gg修改器怎么改成中文 大小:7.17MB7,959人安装 GG修改器中文app是一款非常好用的游戏修改工具,此版本可以将语言设置为中文,为大……
下载
免Root权限GG修改器_gg修改器下载免root权限中文版 大小:17.17MB7,859人安装 大家好,今天小编为大家分享关于免Root权限GG修改器_gg修改器下载免root权限中文版……
下载
中文版的gg修改器在哪里,中文版的GG修改器 大小:4.31MB6,399人安装 如果你是一个游戏爱好者,你肯定知道GG修改器。GG修改器是一个非常受欢迎的修改器,……
下载
gg游戏修改器 吃鸡,GG游戏修改器:吃鸡利器 大小:3.44MB6,812人安装 随着游戏界面的不断升级,很多游戏玩家为了能在游戏里更好的表现和体验,开始使用各……
下载
gg游戏修改器造梦西游OL,gg游戏修改器,让你的梦想成真! 大小:19.41MB6,724人安装 对于喜欢玩游戏的玩家而言,有些游戏往往需要费尽周折才能达成自己的梦想,比如说《……
下载
gg修改器怎么root红米手机,GG修改器:必备root工具之一 大小:17.64MB6,927人安装 如果你是一名玩家,那么你肯定会遇到想要改变游戏里面一些参数的时候。但是,你又被……
下载
gg游戏修改器怎么开美化包,GG游戏修改器美化包 大小:10.65MB6,522人安装 GG游戏修改器是一款众所周知的游戏辅助工具,可以帮助玩家实现一些游戏中难以完成的……
下载
gg修改器真正免root下载_gg修改器免root下载 大小:5.49MB7,801人安装 大家好,今天小编为大家分享关于gg修改器真正免root下载_gg修改器免root下载的内容……
下载